以前的版本有个直接保存URL的功能,现在没有了,改成了从URL中提取,接下来就教大家如何获取:
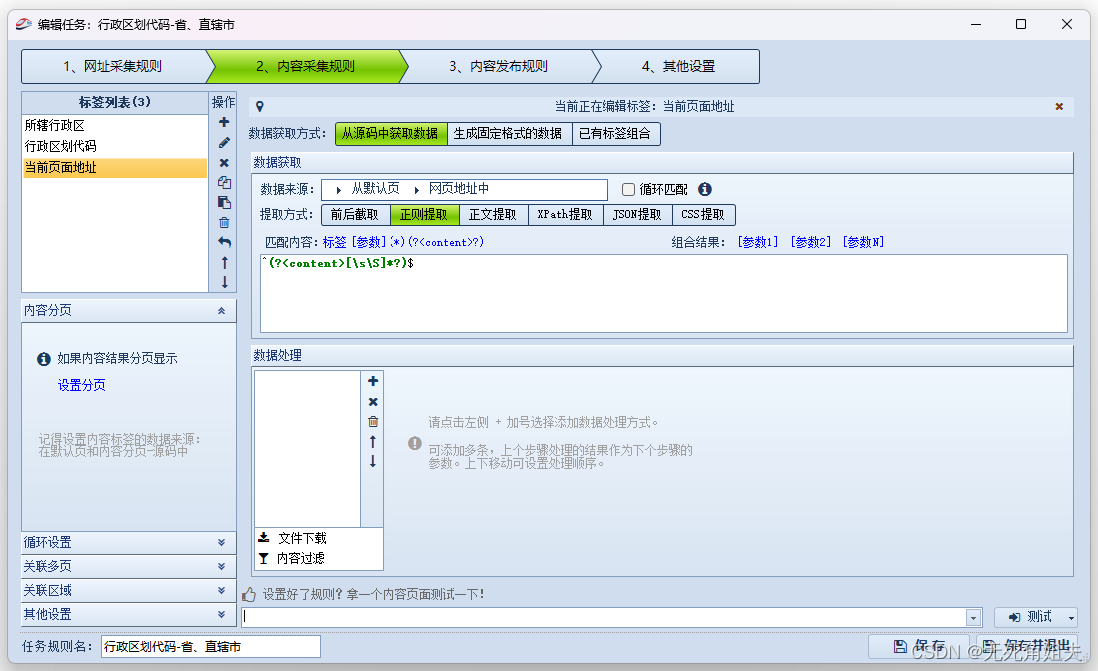
Content:代表内容
?:表示匹配0次或者1次
\s:匹配所有空白字符,包括空格、换行、tab缩进等所有的空白
\S:与\s刚好相反,匹配所有非空白字符
*:修饰匹配次数为 0 次或任意次
[ ]:这个符号,表示在它里面包含的单个字符不限顺序的出现
在正则表达式中,美元符号 用于匹配一行的结尾,比如 " a b c 用于匹配一行的结尾,比如"abc 用于匹配一行的结尾,比如"abc“表示的是以abc结尾的行,”$"表示的是空行。符号是界定符,规定匹配以^后面开头的字符串







