最近我们的团队一直在做帝国CMS模板的排名和一些客户Empire CMS网站的关键词排名,我们已经很努力了,但排名就是上不去,究竟要如何做才能排名上去呢?答案是用光年软件分析数据!
一、什么是光年日志?
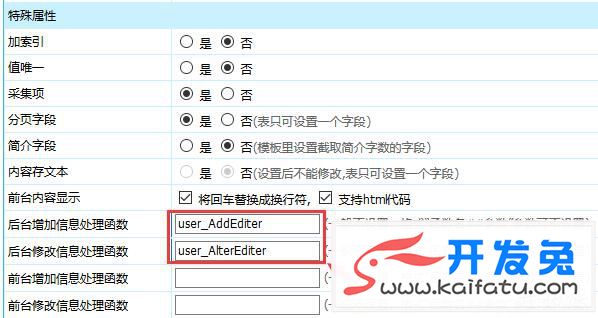
这个工具是比较老的SEO工具了,光年的创始人张国平是比较喜欢用数据说话,以数据指导方向,所以就弄了个系统出来。光年日志分析工具是站长们优化必备的工具。 光年日志分析工具.zip(点击可以下载)
光年日志分析工具.zip(点击可以下载)

光年日志界面
二、什么是网站日志?
1、网站日志是记录web服务器接收处理请求以及运行时错误等各种原始信息的以•log结尾的文件。(网站日志可以用FTP去下载!)




2.通过网站日志可以清楚的得知用户在什么IP、什么时间、用什么操作系统、什么浏览器、什么分辨率设备下访问了网站的哪个页面,是否访问成功。
3.搜索引擎也属于网站中的一类用户,我们今天的分享课,主要是针对搜索引擎这种用户在服务器留下的记录展开分析。为了方便读懂搜索引擎日志,我们需要了解不同搜索引擎蜘蛛的标识,以下为4种搜索引擎的标识——*百度蜘蛛:Baiduspider*搜狗:Sogou News Spider*360:360Spider*谷歌:Googlebot,一般以百度和谷歌蜘蛛为主!
三、如何使用光年软件?
1、解压,打开界面。

2、添加要分析的日志




3、成功完成日志分析。

四、如何分析蜘蛛爬行规律及制定SEO策略?
1、分析软件左面的目录抓取,看看蜘蛛都喜欢去哪个目录抓取,如果她喜欢的目录我们就继续回去对应网站的目录去整改优化;如果出现你不希望蜘蛛访问的目录,那么就去FTP下载robots.txt去禁止它爬行这些目录!


修改robots.txt去禁止它爬行这些目录:(比如img,js,ueditor等我们不希望蜘蛛访问就要限制它)
# # robots.txt for EmpireCMS # User-agent: * template Disallow: /e/ Disallow: /ueditor/ Disallow: /w/ Disallow: /js/ Disallow: /d/ Disallow: /e/class/ Disallow: /e/config/ Disallow: /e/data/ Disallow: /e/enews/ Disallow: /e/update/ Disallow: /templates/ Disallow: /img/ Disallow: /images/ Disallow: /skin/ Disallow: /bb.txt/ Disallow: /ts.php/ Sitemap:

修改好后再把这个robots.txt用FTP重新上传到你的网站,覆盖原来的就行!
2、页面抓取及优化。下图便是蜘蛛爬行过的页面。

从蜘蛛爬行的页面,我们可以知道,这些内容是蜘蛛喜欢的,那么我们就要从这些页面去优化,比如说可以给它增加一些内链,增加一些你网站的关键词!


3、日志文件拆分。
日志数据包含用户数据和蜘蛛数据,我们分析蜘蛛,所以按照蜘蛛的字段,把日志拆分出来,百度蜘蛛字段:baiduspider 谷歌蜘蛛:googlebot 360蜘蛛:360spider。

软件可以把日志文件拆分,按照各种纬度。一般我们比较用得多的是agent字段,就是拆分个个搜索引擎的爬行数据。需要那个搜索引擎的就填他的蜘蛛名称即可,比如baiduspider。
拆出来的文件拖进excel表格。上面红框位置是各个字段的属性意义,比如time下面的就是时间,方便理解。

按照空格分列,分列出来的文件,可以让我们非常清晰的看到蜘蛛的爬行情况。我们一般需要监控的数据。
404:看看我们网站有多少死链接,查到尽快解决掉;
访问次数,停留时间,平均停留时间:看看蜘蛛对我们网站的重视程度,总停留时间相同的情况下,到访次数越少越好(到访次数越少,证明蜘蛛平均停留时间越多)
抓取量:自然是越多越好
不重复抓取:自然是不重复好
每个页面平均抓取时间=总停留时间/抓取量。总停留时间一定的情况下,平均抓取时间越断,抓取量越多……知道为什么要加快服务器速度了吧,蜘蛛抓的快就抓的多啊(当然,还有其他因素)
备注:备注的就是每天备注网站做的比较特殊的调整,或者其他操作。长时间下来可以发现很多问题,比如内部服务器的调整,外部的搜索引擎的调整。
最后:日志数据里面有很多信息,不只我上面所说的那些,你可以针对某一个问题,去查看日志数据,针对解决。
服务器日志数据是目前为止,记录访问者最全的一种数据(最全并不是完整,有时候有的数据是记录不到的),里面有很多信息,看你怎么拆,怎么数量,怎么筛选,排序等等处理数据的方式,能得到不同的数据。你需要的信息都在这里,就看你能不能利用各种处理数据的方式,发现里面的问题。